The previous blog, Existing Open Source for 360-Degree Projection, revealed that different implementations for converting an equirectangular image into rectilinear view could take different amounts of time. This blog post describes a framework that enables exploring different techniques to optimize existing open source options, determining how much faster an optimized algorithm can run, and any tradeoffs needed for those optimizations.
To test different algorithms for converting from an equirectangular to a rectilinear image, the open-source code generally has the following elements, with some being optional when testing how fast a specific algorithm functions:
The code found in the GitHub repository OneDevice implements the elements described above with some enhancements. For instance, some of the tested algorithms take longer during the first iteration due to a need to compile a kernel or pass the kernel to an accelerator in the system, such as a GPU. In cases such as video conversion, this "warmup iteration" happens at the very beginning and has a minor effect on the overall experience; however, this warmup time may be significant for cases where the extraction happens on a single frame. To help distinguish between these two situations, the framework separates the first iteration as a "warmup iteration" and then takes the average of the remaining iterations. This allows the operator to understand how the algorithm will perform for either single frames or a sequence of frames which could either be a video stream or changing as the operator moves the viewport around the scene.
The code that implements the above pseudo-code can be found in OptimizingEquirectangularConversion.cpp. This file uses ParseArg.cpp to parse the command line parameters. Running the executable with the command line flag --help, -h, or -? prints out the full list of available flags and their default values. These can be used to configure the run and specify the algorithm(s) to use, the initial viewing direction, the amount to change that direction with each iteration, the images to use, and so on.
OneDevice.exe -h
Usage: OneDevice.exe [flags]
Where: flags can be zero or more of the following (all flags are case insensitive):
--algorithm=N where N is the number of the algorithm to use during the run. If this is set non-negative, it takes
precedence over --startAlgorithm and --endAlgorithm. Defaults to -1.
-1 = execute algorithms from --startAlgorithm to --endAlgorithm.
0 = Algorithm from https://github.com/rfn123/equirectangular-to-rectlinear/blob/master/Equi2Rect.cpp.
1 = Conversion to C++ of the Python algorithm from
https://github.com/fuenwang/Equirec2Perspec/blob/master/Equirec2Perspec.py
2 = Changed 1 to access m_pXYZPoints by moving a pointer instead of array indexing each time.
3 = Changed 2 to cache m_rotationMatrix instead of array indexing each time.
4 = Single loop point by point conversion from equirectangular to flat.
5 = Computes a Remapping algorithm using oneAPI's DPC++.
6 = Single kernel vs 3 kernels using oneAPI's DPC++.
7 = Computes a Remapping algorithm using oneAPI's DPC++ parallel_for_work_group.
8 = Computes a Remapping algorithm using oneAPI's DPC++ sub-groups to reduce scatter.
9 = Algorithm 6 and optimized ExtractFrame using DPC++.
10 = Algorithm 9 USM but just taking the truncated pixel point.
11 = Algorithm 10 USM but on CPU don't copy memory.
--deltaImage is a flag to indicate that the image should be changed between each iteration to
simulate a video stream.
--deltaPitch=N where N is the amount of pitch to add each iteration (up or down). This can run from
-90 to 90 integer degrees. The negative values are down and positive are up. Default is 0
--deltaRoll=N where N is the amount of roll to add each iteration. This can run from -360 to 360 integer degrees.
Default is 0
--deltaYaw=N where N is the amount of yaw to add each iteration. This can run from -360 to 360 integer degrees.
Default is 0.
--deviceName=value where value is a string to match against device names to
select the best device to run the code on. Other options include:
all - to run on all devices or
list - to list device options. Only used for DPC++ algorithms.
Defaults to empty string (select any)
--driverVersion=value where value is a version number to select. Only used for
DPC++ algorithms. Defaults to empty string (select any)
--endAlgorithm=N where N denotes the last algorithm to run. Use -1 to run to end of all algorithms.
Defaults to -1
--fov the number of integer degrees wide to use when flattening the image. This can be from 1 to 120. Default is 60.
--heightOutput=N where N is the number of pixels height the flattened image will be. Default is 540.
--help|-h|-? means to display the usage message
--img0=filePath where filePath is the path to an equirectangular image to load for the first frame.
Defaults to ..\..\..\images\IMG_20230629_082736_00_095.jpg.
--img1=filePath where filePath is the path to an equirectangular image to load for the second frame.
Defaults to ..\..\..\images\ImageAndOverlay - equirectangular.jpg.
--iterations=N where N is the number of iterations. Defaults to 0 (interactive)
--platformName=value where value is a string to match against platform names.
Other options include:
all - to run on all platforms or
list - to list the platforms.
Only used for DPC++ algorithms. Defaults to empty string (select any)
--pitch=N where N is the pitch of the viewer's perspective (up or down). This can run from
-90 to 90 integer degrees. The negative values are down and positive are up. 0 is straight ahead. Default is 0
--roll=N where N defines how level the camera is. This can run from 0 to 360 degrees. The rotation is counter
clockwise so 90 integer degrees will lift the right side of the 'camera' up to be on top. 180 will flip the
'camera' upside down. 270 will place the left side of the camera on top. Default is 0
--startAlgorithm=N where N defines the first algorithm number to run and then all algorithms up to and including
--endAlgorithm will be run in succession. Defaults to 0.
--showFrames indicates each calculated frame should be shown. Defaults to true for interactive mode, false otherwise.
--typePreference=type1;type2;... where the types can be CPU, GPU, or
ACC (for Accelerator such as FPGA. type1 is highest preference, then type2, etc.
--widthOutput=N where N is the number of pixels width the flattened image will be. Default is 1080.
--yaw=N where N defines the yaw of the viewer's perspective (left or right angle). This can run from
-180 to 180 integer degrees. Negative values are to the left of center and positive to the right. 0 is
straight ahead (center of equirectangular image). Default is 0.
The file TimingStats.cpp contains a class that can be called periodically as the code executes to capture the amount of time different steps in the algorithm take to execute. This class manages the warmup times, summing and averaging multiple iterations after warm up, and reporting out the information.
The framework includes a BaseAlgorithm.cpp that defines an abstract base class that has pure virtual functions indicating what the inheriting classes must implement so the framework can call the algorithm implementations. Aside from the constructor and destructor, the base class has functions for the following:
Most other files in the framework contain classes derived from the base class above and implement various algorithms for extracting a rectilinear image from an equirectangular image. The following sections of this blog describe the algorithms.
The framework supports an interactive mode to assist with debugging and checking implemented algorithms for correct behaviors. Placing the flag --iterations=0 on the command line launches in interactive mode. The framework initializes according to all other command line flags, runs the first algorithm, and then presents the rectilinear image in a window. The person running the code can manually interact using that window to change many parameters, and the displayed image will update accordingly. The framework supports changing the yaw, pitch, and roll. An internal "delta" value determines how many degrees to move in a selected direction to provide maximum control. This value is initialized to 10 but can be altered using keystrokes described below. The accepted keys include:
The first algorithm utilizes the concepts from https://github.com/rfn123/equirectangular-to-rectlinear/blob/master/Equi2Rect.cpp and folds them into a derived class for the framework. A code execution returns the output shown below. The first line of the output shows the command used to produce the subsequent output. The --algorithm=0 selects algorithm zero to be used during the run. The --iterations flag tells the program to run 101 total iterations, with the first being a warmup and the remaining one hundred for averaging the results. The --yaw, --pitch, and --roll values define the initial viewport direction. The --deltaYaw tells how many degrees to add to the viewport viewing direction with each new iteration, so iteration two will have a yaw of the initial 10 plus another 10, so it will point at 20 degrees to the right of center. The next iteration will be 30 degrees, and so on. The --typePreference selects the type of processor to use for the calculations; however, note that this flag is ignored for any algorithm not using Data Parallel C++. The final --img flags select the images to load.
The framework provides the ability to time different portions of a code run. The warmup rows represent results from the first run of the algorithm. Sometimes, this takes longer than subsequent runs due to allocating and initializing memory, selecting and compiling the correct kernel to run (discussed later), and other startup tasks.
The "times averaging" rows report the average of the remaining N-1 runs; in this case, N = 1001. Running multiple iterations smooths out the results since a single run may get swapped out during the calculation or take a bit longer than others as it executes. Generally speaking, averaging a sufficiently large number of iterations makes the results easier to compare and less susceptible to anomalies.
The "lap averaging" rows combine the warmup and times averaging to get the total picture of a run from start to finish across the full N iterations.
All of the above averages use the time within the function to compute an "instantaneous" FPS result that does not consider any other logic outside the specific computation functions. The total averaging row takes the full execution time, including all the supporting setup time, and calculates the perceived FPS by the person operating the code. When everything is executing on a single device (CPU or GPU), the total averaging tends to be a lower FPS rate than the times averaging or the lap averaging since it takes longer for the entire loop of code to run compared to the individual functions. When code is executed on two devices described later in the blog series, the perceived time may be shorter than the computational times since the computations on two devices happen in parallel.
The summary lines are repeats of the warmup and times averaging rows for summarizing the results of processing an image frame. They are repeated for convenience so the person executing the code can quickly see the algorithm's frame-per-second (FPS) results.
Notice that all rows are comma-separated variables (CSV). This makes it easy to copy/paste the results into a program like Excel for further analysis.
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=0 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=CPU --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
Loading Image0
Loading Image1
Images loaded.
Algorithm description: V1 Equi2Rect reprojection.
warmup, 1, Class initialization, 0.00054740,s, 0.54740,ms, 547.400,us,
warmup, 1, Variant initialization, 0.00000460,s, 0.00460,ms, 4.600,us,
warmup, 1, Frame Calculations, 0.00171000,s, 1.71000,ms, 1710.000,us,
warmup, 1, Image extraction, 1.08332820,s, 1083.32820,ms, 1083328.200,us,
warmup, 1, frame(s), 1.08504090,s, 1085.04090,ms, 1085040.900,us, FPS, 0.9216242
times averaging, 1000, Frame Calculations, 0.00000466,s, 0.00466,ms, 4.662,us,
times averaging, 1000, Image extraction, 1.07838461,s, 1078.38461,ms, 1078384.611,us,
times averaging, 1000, frame(s), 1.07839043,s, 1078.39043,ms, 1078390.427,us, FPS, 0.9273079
lap averaging, 1001, Frame Calculations, 0.00000637,s, 0.00637,ms, 6.366,us,
lap averaging, 1001, Image extraction, 1.07838955,s, 1078.38955,ms, 1078389.549,us,
lap averaging, 1001, frame(s), 1.07839707,s, 1078.39707,ms, 1078397.071,us, FPS, 0.9273022
total averaging, 1001, Total, 1.07839733,s, 1078.39733,ms, 1078397.329,us, FPS, 0.9273020
All done! Summary of all runs:
V1 Equi2Rect reprojection.
warmup, 1, frame(s), 1.08504090,s, 1085.04090,ms, 1085040.900,us, FPS, 0.9216242
times averaging, 1000, frame(s), 1.07839043,s, 1078.39043,ms, 1078390.427,us, FPS, 0.9273079
total averaging, 1001, Total, 1.07839733,s, 1078.39733,ms, 1078397.329,us, FPS, 0.9273020
As shown above, the framework supplies information about the various image processing stages. The Class initialization times record the time it takes to instantiate the class that implements a particular algorithm.
Within the framework, each class implementing an algorithm may have different variants. Consider these minor variations on an algorithm being tested to see which is more efficient. For instance, variations may store data in memory differently, such as array of structures, structure of arrays, row/column order, column/row order, etc. To support these variations, after class instantiation, the StartVariant is called for each variation. The Variant initializations report how long it takes to do this initialization.
The Frame Calculations represent how long the algorithm calculates the frame or the pixel locations to extract from the equirectangular image to create a rectilinear view for a given viewing port. In some cases, as is the case above, the algorithm does not pre-compute the frame information; thus, the length of time is short. But as shown later, other algorithms pre-compute the frame information and may cache this information to optimize for video streams or other cases where the viewing direction does not change, but the underlying equirectangular image does change.
The Image extraction tells how long the algorithm takes to copy all the appropriate pixels from the equirectangular image into the new rectilinear image.
The frame(s) row reports how long it takes to do all the work to extract a frame. This row also reports the maximum frame-per-second rate that could be achieved by this algorithm, assuming that nothing else was happening in the overall workflow. This is unrealistic in an actual workflow since the extracted image must be displayed to the person using the program. Still, it gives a well-defined metric to use when comparing the efficiency of one algorithm versus another.
The same Intel® i9-9900k machine was used to execute the program as was used in the previous blog that introduced this code. The yellow highlighted FPS (0.9273079) is similar to the previous stand-alone results (0.89846216), so incorporating the code into the framework did not introduce substantial overhead.
The second algorithm ports the concepts from the Python code found in https://github.com/fuenwang/Equirec2Perspec/blob/master/Equirec2Perspec.py into a derived class for this framework. In this case, two variations were created to test whether row/column or column/row layout is better. Thus, the results shown below report on both variations. The row/column layout is faster by about 8 FPS. This is primarily because OpenCV represents images in row/column format; thus, storing results in column/row format in the algorithm forces an additional step of transposing from column/row to row/column for the extraction phase.
For this algorithm, extra code was added to report the time the three key function calls take (Create XYZ Coords, Create Lon Lat Coords, and Create XY Coords) and the extra Create Map step required to transpose the map. As can be seen, the Create Map step in the second variant accounts for 1.77984 milliseconds on average, and this step alone accounts for the majority of the slowdown (i.e., if we take the overall frame time (16.79339) and subtract the Create Map time (1.77984), the frame time would take 15.01355, which is similar to the row/column frame time of 14.82140 milliseconds for the first variant).
Comparing the FPS results below against the original Python results shows the C++ implementation to be about 5.7 times faster (i.e., 67.4700178 / 11.821199533998858).
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=1 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=CPU --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
Loading Image0
Loading Image1
Images loaded.
Algorithm description: V1a Multiple loop serial point-by-point conversion from equirectangular to flat. Memory array of structure row/column layout.
warmup, 1, Class initialization, 0.00000450,s, 0.00450,ms, 4.500,us,
warmup, 1, Variant initialization, 0.00004560,s, 0.04560,ms, 45.600,us,
warmup, 1, Create XYZ Coords, 0.00222730,s, 2.22730,ms, 2227.300,us,
warmup, 1, Create Lon Lat Coords, 0.01442760,s, 14.42760,ms, 14427.600,us,
warmup, 1, Create XY Coords, 0.00194850,s, 1.94850,ms, 1948.500,us,
warmup, 1, Frame Calculations, 0.01861200,s, 18.61200,ms, 18612.000,us,
warmup, 1, Remap, 0.00945840,s, 9.45840,ms, 9458.400,us,
warmup, 1, Image extraction, 0.00945890,s, 9.45890,ms, 9458.900,us,
warmup, 1, frame(s), 0.02807420,s, 28.07420,ms, 28074.200,us, FPS, 35.6198930
times averaging, 1000, Create XYZ Coords, 0.00054643,s, 0.54643,ms, 546.431,us,
times averaging, 1000, Create Lon Lat Coords, 0.01073178,s, 10.73178,ms, 10731.780,us,
times averaging, 1000, Create XY Coords, 0.00065189,s, 0.65189,ms, 651.894,us,
times averaging, 1000, Frame Calculations, 0.01193053,s, 11.93053,ms, 11930.530,us,
times averaging, 1000, Remap, 0.00269910,s, 2.69910,ms, 2699.101,us,
times averaging, 1000, Image extraction, 0.00288956,s, 2.88956,ms, 2889.561,us,
times averaging, 1000, frame(s), 0.01482140,s, 14.82140,ms, 14821.398,us, FPS, 67.4700178
lap averaging, 1001, Create XYZ Coords, 0.00054811,s, 0.54811,ms, 548.110,us,
lap averaging, 1001, Create Lon Lat Coords, 0.01073547,s, 10.73547,ms, 10735.472,us,
lap averaging, 1001, Create XY Coords, 0.00065319,s, 0.65319,ms, 653.189,us,
lap averaging, 1001, Frame Calculations, 0.01193721,s, 11.93721,ms, 11937.205,us,
lap averaging, 1001, Remap, 0.00270585,s, 2.70585,ms, 2705.853,us,
lap averaging, 1001, Image extraction, 0.00289612,s, 2.89612,ms, 2896.124,us,
lap averaging, 1001, frame(s), 0.01483464,s, 14.83464,ms, 14834.638,us, FPS, 67.4098024
total averaging, 1001, Total, 0.01483488,s, 14.83488,ms, 14834.884,us, FPS, 67.4086857
Algorithm description: V1a Multiple loop serial point-by-point conversion from equirectangular to flat. Memory array of structure column/row layout.
warmup, 1, Class initialization, 0.00000450,s, 0.00450,ms, 4.500,us,
warmup, 1, Variant initialization, 0.00004020,s, 0.04020,ms, 40.200,us,
warmup, 1, Create XYZ Coords, 0.00212270,s, 2.12270,ms, 2122.700,us,
warmup, 1, Create Lon Lat Coords, 0.01130650,s, 11.30650,ms, 11306.500,us,
warmup, 1, Create XY Coords, 0.00171640,s, 1.71640,ms, 1716.400,us,
warmup, 1, Frame Calculations, 0.01514570,s, 15.14570,ms, 15145.700,us,
warmup, 1, Create Map, 0.00208630,s, 2.08630,ms, 2086.300,us,
warmup, 1, Remap, 0.00312290,s, 3.12290,ms, 3122.900,us,
warmup, 1, Image extraction, 0.00533190,s, 5.33190,ms, 5331.900,us,
warmup, 1, frame(s), 0.02047830,s, 20.47830,ms, 20478.300,us, FPS, 48.8321785
times averaging, 1000, Create XYZ Coords, 0.00053543,s, 0.53543,ms, 535.429,us,
times averaging, 1000, Create Lon Lat Coords, 0.01063900,s, 10.63900,ms, 10639.004,us,
times averaging, 1000, Create XY Coords, 0.00064727,s, 0.64727,ms, 647.272,us,
times averaging, 1000, Frame Calculations, 0.01182214,s, 11.82214,ms, 11822.140,us,
times averaging, 1000, Create Map, 0.00177984,s, 1.77984,ms, 1779.843,us,
times averaging, 1000, Remap, 0.00306457,s, 3.06457,ms, 3064.568,us,
times averaging, 1000, Image extraction, 0.00496970,s, 4.96970,ms, 4969.697,us,
times averaging, 1000, frame(s), 0.01679339,s, 16.79339,ms, 16793.390,us, FPS, 59.5472375
lap averaging, 1001, Create XYZ Coords, 0.00053701,s, 0.53701,ms, 537.014,us,
lap averaging, 1001, Create Lon Lat Coords, 0.01063967,s, 10.63967,ms, 10639.671,us,
lap averaging, 1001, Create XY Coords, 0.00064834,s, 0.64834,ms, 648.340,us,
lap averaging, 1001, Frame Calculations, 0.01182546,s, 11.82546,ms, 11825.460,us,
lap averaging, 1001, Create Map, 0.00178015,s, 1.78015,ms, 1780.149,us,
lap averaging, 1001, Remap, 0.00306463,s, 3.06463,ms, 3064.626,us,
lap averaging, 1001, Image extraction, 0.00497006,s, 4.97006,ms, 4970.059,us,
lap averaging, 1001, frame(s), 0.01679707,s, 16.79707,ms, 16797.072,us, FPS, 59.5341872
total averaging, 1001, Total, 0.01679729,s, 16.79729,ms, 16797.288,us, FPS, 59.5334195
All done! Summary of all runs:
V1a Multiple loop serial point-by-point conversion from equirectangular to flat. Memory array of structure row/column layout.
warmup, 1, frame(s), 0.02807420,s, 28.07420,ms, 28074.200,us, FPS, 35.6198930
times averaging, 1000, frame(s), 0.01482140,s, 14.82140,ms, 14821.398,us, FPS, 67.4700178
total averaging, 1001, Total, 0.01483488,s, 14.83488,ms, 14834.884,us, FPS, 67.4086857
V1a Multiple loop serial point by point conversion from equirectangular to flat. Memory array of structure column/row layout.
warmup, 1, frame(s), 0.02047830,s, 20.47830,ms, 20478.300,us, FPS, 48.8321785
times averaging, 1000, frame(s), 0.01679339,s, 16.79339,ms, 16793.390,us, FPS, 59.5472375
total averaging, 1001, Total, 0.01679729,s, 16.79729,ms, 16797.288,us, FPS, 59.5334195
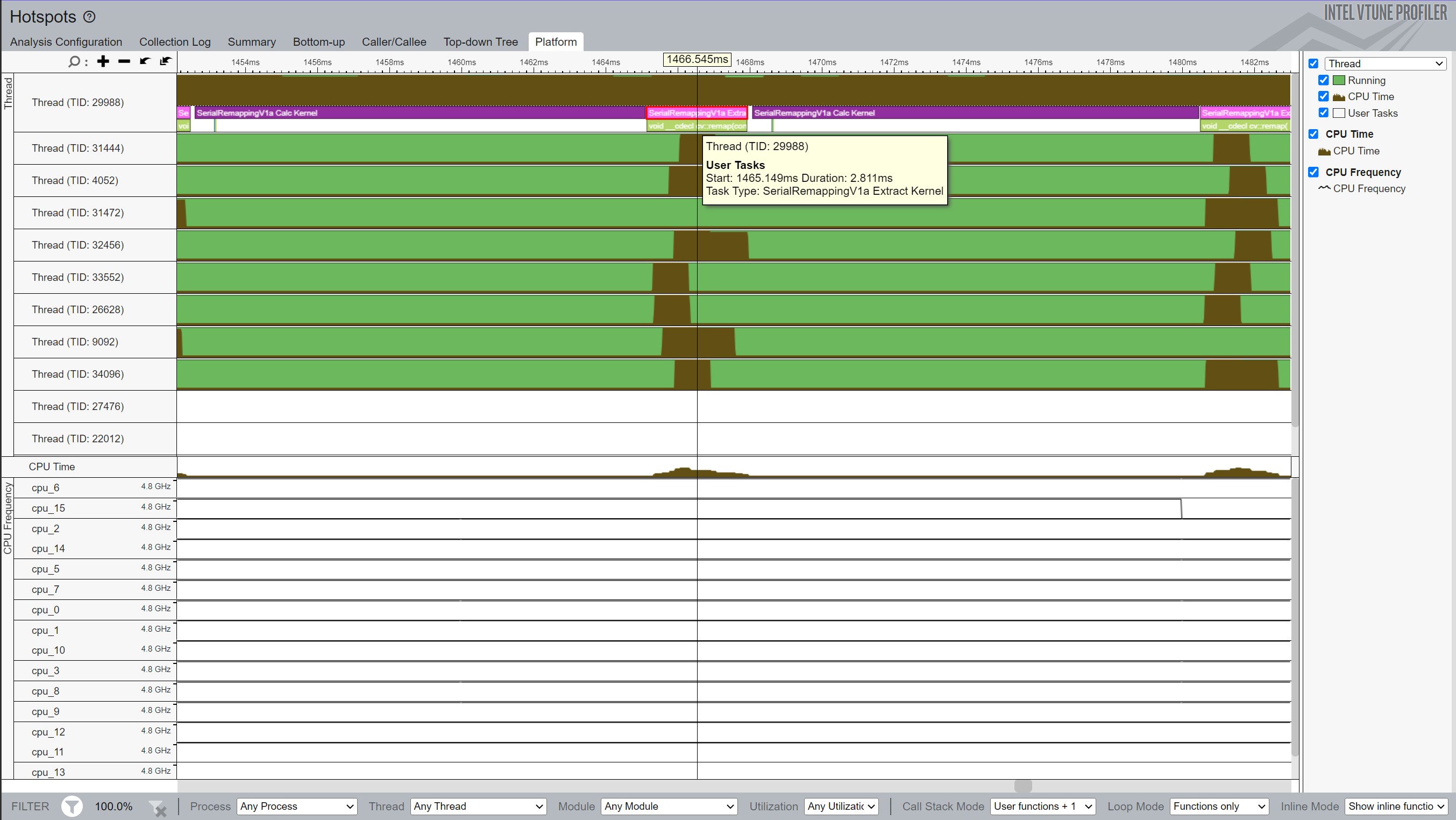
As introduced in the previous blog, Intel® VTune Profiler assists developers in visualizing code behavior and execution duration of functions. The code framework takes advantage of a very useful feature of VTune where labels can be included in the to identify regions of interest in the code (e.g., to delineate part of the code that might be inefficient or compare two code regions to determine which takes more time to execute).
Figure 1 shows a zoomed in view of two frame extractions. By identifying the code that does the Frame Calculations and another section that does the Frame Extraction, VTune displays these regions in its output (i.e., the purple and pink labels in the top thread). This makes it easy to see the relative difference in time it takes for each region of code. Hovering over the labels pops up a tool tip that informs the user the amount of execution time. VTune provides further evidence that the frame extraction takes around 2.8 ms to complete, which corresponds closely with the 2.88 reported as the average time for Frame Calculations with the row/column memory layout.
For clarity and to allow disabling of VTune calls entirely, #ifdef VTUNE_API and #endif pairs surround the VTune calls. Thus, for a full understanding of using VTune labeling, search the code base for VTUNE_API. As a brief introduction, VTune requires a domain and one or more labels. In the code snippets below, the first group of code creates a global variable to contain the domain. This can be defined in the primary code file. The comments describe additional steps that must be taken to configure the Visual Studio project to access VTune's include and library files. Change VTUNE_PROFILER_2023_DIR to correspond to whichever version you installed.
The second snippet assumes it exists in another c++ code file so it uses the extern keyword on the domain to have access to that variable. In a very simple project where there is only one file, the two code snippets could be merged and the extern line would be dropped. The second snippet creates the label strings that were used in Figure 1. Create as many labels as are required to track code regions of interest.
#ifdef VTUNE_API
// Assuming you have 2023 of VTune installed, you will need to add
// $(VTUNE_PROFILER_2023_DIR)\sdk\include
// to the include directories for any configurations that will be profiled. Also add
// $(VTUNE_PROFILER_2023_DIR)\sdk\lib64
// to the linker additional directories area
#include "ittnotify.h"
#pragma comment(lib, "libittnotify.lib")
__itt_domain* pittTests_domain = __itt_domain_createA("localDomain");
#endif
#ifdef VTUNE_API
#include "ittnotify.h"
#pragma comment(lib, "libittnotify.lib")
extern __itt_domain *pittTests_domain;
// Create string handle for denoting when the kernel is running
wchar_t const *pSerialRemappingV1aExtract = _T("SerialRemappingV1a Extract Kernel");
__itt_string_handle *handle_SerialRemappingV1a_extract_kernel = __itt_string_handle_create(pSerialRemappingV1aExtract);
wchar_t const *pSerialRemappingV1aCalc = _T("SerialRemappingV1a Calc Kernel");
__itt_string_handle *handle_SerialRemappingV1a_calc_kernel = __itt_string_handle_create(pSerialRemappingV1aCalc);
#endif
Finally, surround the code segments of interest with __itt_task_begin and __itt_task_end calls as shown below.
#ifdef VTUNE_API
__itt_task_begin(pittTests_domain, __itt_null, __itt_null, handle_SerialRemappingV1a_extract_kernel);
#endif
// Code to be identified by VTune with the given label goes here
#ifdef VTUNE_API
__itt_task_end(pittTests_domain);
#endif
Since Algorithm 1 pre-computes and stores the pixel address information for a given viewing direction, this information can substantially accelerate image extraction for subsequent frames if the viewing direction does not change. For instance, if the underlying frames come from a video or a person is viewing a series of images and wishes to extract the same viewing direction from each, then this algorithm trades memory usage for speed.
In the output below, the --deltaYaw=10 was removed from the command line, and the --deltaImage was added. The --deltaImage causes the framework to alternate each extraction between --img0 and --img1 to simulate video or multiple stills with the same viewing direction. As highlighted below, this increases the FPS rate to 355.4009988 which is about 30 times faster than the original Python extraction speed for this specific usage scenario (i.e., 355.4009988 / 11.821199533998858).
Notice that the warmup iteration must include the Frame Calculations since that is where the pixel addresses are calculated, but for all the "times averaging" rows, the time spent is minuscule (i.e., a function call and a set of comparisons to ensure the viewing direction has not changed). If nothing changes, the already cached frame extraction coordinates can be reused.
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=1 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaImage --typePreference=CPU --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
Loading Image0
Loading Image1
Images loaded.
Algorithm description: V1a Multiple loop serial point by point conversion from equirectangular to flat. Memory array of structure row/column layout.
warmup, 1, Class initialization, 0.00000440,s, 0.00440,ms, 4.400,us,
warmup, 1, Variant initialization, 0.00004450,s, 0.04450,ms, 44.500,us,
warmup, 1, Create XYZ Coords, 0.00225770,s, 2.25770,ms, 2257.700,us,
warmup, 1, Create Lon Lat Coords, 0.01194410,s, 11.94410,ms, 11944.100,us,
warmup, 1, Create XY Coords, 0.00181920,s, 1.81920,ms, 1819.200,us,
warmup, 1, Frame Calculations, 0.01602420,s, 16.02420,ms, 16024.200,us,
warmup, 1, Remap, 0.00939080,s, 9.39080,ms, 9390.800,us,
warmup, 1, Image extraction, 0.00939140,s, 9.39140,ms, 9391.400,us,
warmup, 1, frame(s), 0.02541870,s, 25.41870,ms, 25418.700,us, FPS, 39.3411150
times averaging, 1000, Frame Calculations, 0.00000021,s, 0.00021,ms, 0.208,us,
times averaging, 1000, Remap, 0.00265969,s, 2.65969,ms, 2659.692,us,
times averaging, 1000, Image extraction, 0.00281265,s, 2.81265,ms, 2812.651,us,
times averaging, 1000, frame(s), 0.00281372,s, 2.81372,ms, 2813.723,us, FPS, 355.4009988
lap averaging, 1, Create XYZ Coords, 0.00225770,s, 2.25770,ms, 2257.700,us,
lap averaging, 1, Create Lon Lat Coords, 0.01194410,s, 11.94410,ms, 11944.100,us,
lap averaging, 1, Create XY Coords, 0.00181920,s, 1.81920,ms, 1819.200,us,
lap averaging, 1001, Frame Calculations, 0.00001622,s, 0.01622,ms, 16.216,us,
lap averaging, 1001, Remap, 0.00266642,s, 2.66642,ms, 2666.416,us,
lap averaging, 1001, Image extraction, 0.00281922,s, 2.81922,ms, 2819.223,us,
lap averaging, 1001, frame(s), 0.00283631,s, 2.83631,ms, 2836.305,us, FPS, 352.5713298
total averaging, 1001, Total, 0.00283654,s, 2.83654,ms, 2836.541,us, FPS, 352.5420749
Algorithm description: V1a Multiple loop serial point by point conversion from equirectangular to flat. Memory array of structure column/row layout.
warmup, 1, Class initialization, 0.00000440,s, 0.00440,ms, 4.400,us,
warmup, 1, Variant initialization, 0.00004320,s, 0.04320,ms, 43.200,us,
warmup, 1, Create XYZ Coords, 0.00222200,s, 2.22200,ms, 2222.000,us,
warmup, 1, Create Lon Lat Coords, 0.01238700,s, 12.38700,ms, 12387.000,us,
warmup, 1, Create XY Coords, 0.00183970,s, 1.83970,ms, 1839.700,us,
warmup, 1, Frame Calculations, 0.01644900,s, 16.44900,ms, 16449.000,us,
warmup, 1, Create Map, 0.00212530,s, 2.12530,ms, 2125.300,us,
warmup, 1, Remap, 0.00307680,s, 3.07680,ms, 3076.800,us,
warmup, 1, Image extraction, 0.00533200,s, 5.33200,ms, 5332.000,us,
warmup, 1, frame(s), 0.02178190,s, 21.78190,ms, 21781.900,us, FPS, 45.9096773
times averaging, 1000, Frame Calculations, 0.00000017,s, 0.00017,ms, 0.173,us,
times averaging, 1000, Create Map, 0.00187661,s, 1.87661,ms, 1876.607,us,
times averaging, 1000, Remap, 0.00296983,s, 2.96983,ms, 2969.835,us,
times averaging, 1000, Image extraction, 0.00497003,s, 4.97003,ms, 4970.026,us,
times averaging, 1000, frame(s), 0.00497128,s, 4.97128,ms, 4971.278,us, FPS, 201.1555258
lap averaging, 1, Create XYZ Coords, 0.00222200,s, 2.22200,ms, 2222.000,us,
lap averaging, 1, Create Lon Lat Coords, 0.01238700,s, 12.38700,ms, 12387.000,us,
lap averaging, 1, Create XY Coords, 0.00183970,s, 1.83970,ms, 1839.700,us,
lap averaging, 1001, Frame Calculations, 0.00001660,s, 0.01660,ms, 16.605,us,
lap averaging, 1001, Create Map, 0.00187686,s, 1.87686,ms, 1876.855,us,
lap averaging, 1001, Remap, 0.00296994,s, 2.96994,ms, 2969.942,us,
lap averaging, 1001, Image extraction, 0.00497039,s, 4.97039,ms, 4970.388,us,
lap averaging, 1001, frame(s), 0.00498807,s, 4.98807,ms, 4988.072,us, FPS, 200.4782759
total averaging, 1001, Total, 0.00498829,s, 4.98829,ms, 4988.291,us, FPS, 200.4694550
All done! Summary of all runs:
V1a Multiple loop serial point by point conversion from equirectangular to flat. Memory array of structure row/column layout.
warmup, 1, frame(s), 0.02541870,s, 25.41870,ms, 25418.700,us, FPS, 39.3411150
times averaging, 1000, frame(s), 0.00281372,s, 2.81372,ms, 2813.723,us, FPS, 355.4009988
total averaging, 1001, Total, 0.00283654,s, 2.83654,ms, 2836.541,us, FPS, 352.5420749
V1a Multiple loop serial point by point conversion from equirectangular to flat. Memory array of structure column/row layout.
warmup, 1, frame(s), 0.02178190,s, 21.78190,ms, 21781.900,us, FPS, 45.9096773
times averaging, 1000, frame(s), 0.00497128,s, 4.97128,ms, 4971.278,us, FPS, 201.1555258
total averaging, 1001, Total, 0.00498829,s, 4.98829,ms, 4988.291,us, FPS, 200.4694550
Algorithm 2 contains a minor modification of the Algorithm 1 code. Algorithm 1 uses array indexing to access the pixel values, as shown below.
for (int y = 0; y < m_parameters->m_heightOutput; y++)
{
Point3D *pRow = &m_pXYZPoints[y * m_parameters->m_widthOutput];
for (int x = 0; x < m_parameters->m_widthOutput; x++)
{
pRow[x].m_x = x * invf + translatecx;
pRow[x].m_y = y * invf + translatecy;
pRow[x].m_z = 1.0f;
}
}
As shown below, Algorithm 2 replaces array indexing with code that gets the first-pixel location and then increments the pointer once at the end of each loop versus computing the [x] offset three times during the loop.
Point3D* pElement = &m_pXYZPoints[0];
for (int y = 0; y < m_parameters->m_heightOutput; y++)
{
for (int x = 0; x < m_parameters->m_widthOutput; x++)
{
pElement->m_x = x * invf + translatecx;
pElement->m_y = y * invf + translatecy;
pElement->m_z = 1.0f;
pElement++;
}
}
However, Algorithm 2 (67.5261480 FPS) performs about the same as Algorithm 1 (67.4700178 FPS). See the output below from Algorithm 2 (only the summary lines are presented for brevity). Either the multiple additions from Algorithm 1 computing the array index offset are inconsequential, or the compiler optimizes this code properly.
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=2 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=CPU --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
All done! Summary of all runs:
V1b = Changed V1a to access m_pXYZPoints by moving a pointer instead of array indexing each time. Memory array of structure row/column layout.
warmup, 1, frame(s), 0.02526620,s, 25.26620,ms, 25266.200,us, FPS, 39.5785674
times averaging, 1000, frame(s), 0.01480908,s, 14.80908,ms, 14809.078,us, FPS, 67.5261480
total averaging, 1001, Total, 0.01481985,s, 14.81985,ms, 14819.853,us, FPS, 67.4770533
V1b = Changed V1a to access m_pXYZPoints by moving a pointer instead of array indexing each time. Memory array of structure column/row layout.
warmup, 1, frame(s), 0.02068500,s, 20.68500,ms, 20685.000,us, FPS, 48.3442108
times averaging, 1000, frame(s), 0.01678843,s, 16.78843,ms, 16788.432,us, FPS, 59.5648249
total averaging, 1001, Total, 0.01679259,s, 16.79259,ms, 16792.588,us, FPS, 59.5500817
Algorithm 3 resulted from exploring the code using the Intel® Advisor tool, which runs the executable and monitors the code's behavior. Advisor has several profile settings to provide: 1) a general survey, 2) characterization of trip counts, Floating Point Operations Per Second (FLOPS), and call stacks, 3) memory access patterns, and/or 4) dependencies. Advisor can profile an execution without modifying the code; however, it also supports an Application Programming Interface (API) that allows a programmer to inform Advisor about code sections to profile.
The Intel® oneAPI Base Toolkit (https://www.intel.com/content/www/us/en/developer/tools/oneapi/toolkits.html) includes Advisor. Alternatively, a stand-alone version is available at https://www.intel.com/content/www/us/en/developer/articles/tool/oneapi-standalone-components.html#advisor. Regardless of the selected download option, the tool is free.
Figure 2 below shows a screen capture from Advisor after profiling Algorithm 1 in Debug Mode. The upper part of the figure contains the Roofline analysis. Three regions are shown in shades of pink: 1) Memory-bound functions and loops on the left, 2) Bound by computer and memory roofs in the center, and 3) Compute bound on the right. Functions and loops falling in the Memory region are throttled due to requiring memory access, and the CPU remains capable of processing more data than can be provided by the memory accesses. The central zone shows functions that may be capped by memory accesses or by compute speed depending on which memory type of memory is being accessed (DRAM, Level 1, Level 2, or Level 3 cache) and which instruction sets are being utilized (Scaler Add, Vector Add, or Fused Multiply Add (FMA)). The Compute bound zone receives plenty of data from appropriate memory sources, and the CPU computational capabilities are the bottleneck.
Within the Roofline plot, each circle represents one of the loops or functions shown in the lower portion of the application. Advisor categorizes each as: 1) Green if the code is not called a lot or if it is not taking a lot of processing time (i.e., the effort the optimize any of these will not result in large reductions in the overall time taken to compute an answer), 2) Yellow dots represent code that merits taking a look at, but the gains will be lower than the red dots, 3) Red dots showcase code that would provide the maximum return on investment since optimizing those elements provides the largest processing gains, if successful.
For each of the three regions in advisor, if a line is drawn directly upward, it will intersect with one or more lines above the dot. Each line represents either a type of memory access (the diagonal lines) or a specific compute type (the horizontal lines). To get above any of these lines, the code must be changed to take advantage of a different type of memory access (to get above a diagonal line) or compute type (to get above a horizontal line).
The large red dot selected in the figure below represents calls to cv::Mat::at, which accesses elements within a 2D matrix. Advisor explains that the performance is currently at 3.5 GigaOPS. If the function could utilize more data from the L3 cache, it could execute at a maximum of 29.87 GigaOPS, whereas if the L1 cache could be utilized, it would jump up to 186.4 GigaOPS. Notice that the scale of both axes of the Roofline graph is logarithmic, so moving further up or right makes significant gains.
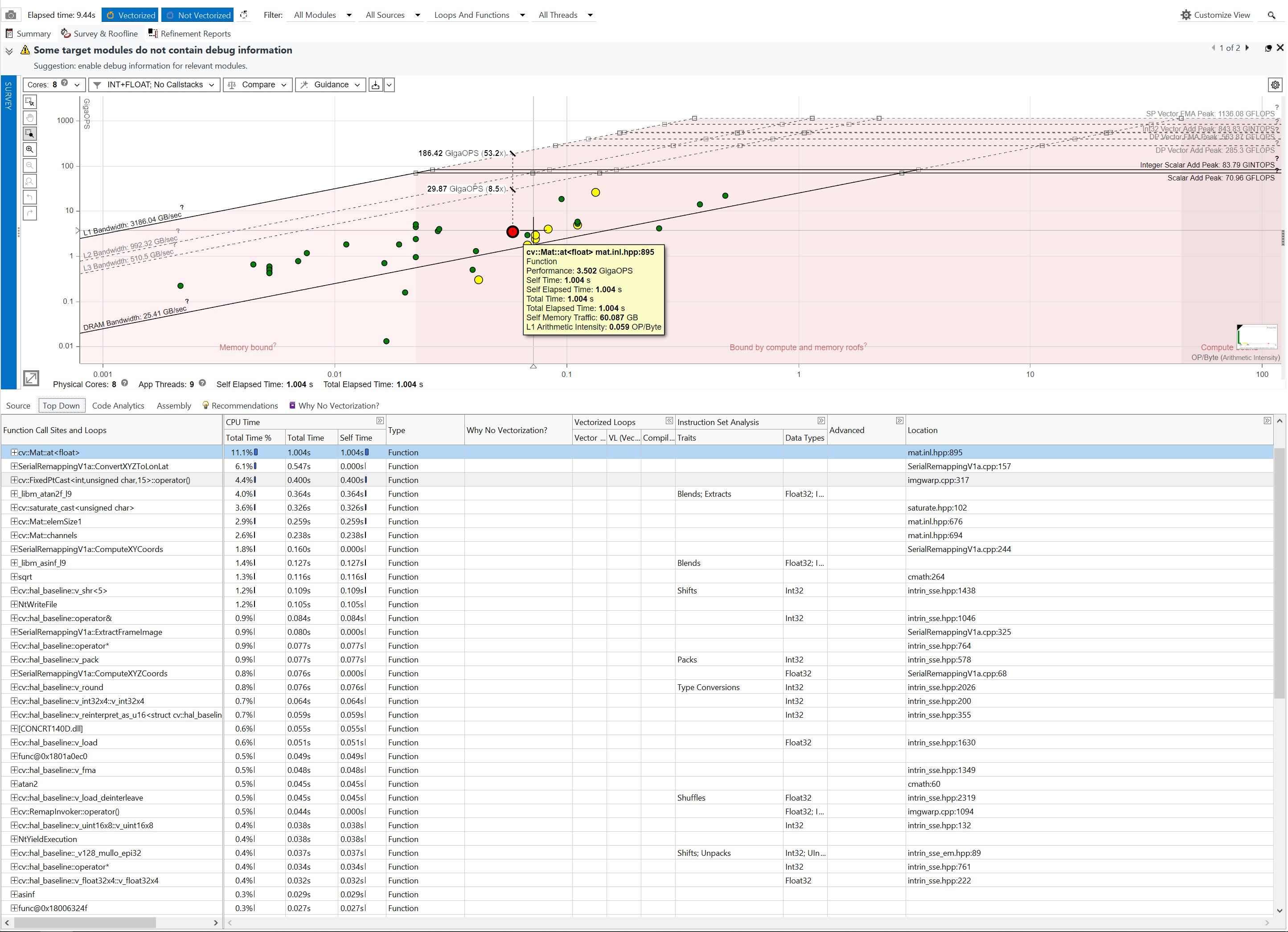
One option would be to investigate improving the performance of the at function; however, that code resides in the OpenCV code base, so making changes there would be harder. Thus, the code was reviewed for this coding effort to see if the number of calls to the "at" function could be reduced. Within Algorithm 1 (and 2), the code calling the "at" function looks like the following. Since the 9 calls to "at" are inside a double loop, each is called m_heightOutput * m_widthOutput times. The code run through Advisor was configured to have the width at 1080 and height at 540, resulting in 1080 * 540 * 9 = 5,248,800 calls to "at".
for (int y = 0; y < m_parameters->m_heightOutput; y++)
{
for (int x = 0; x < m_parameters->m_widthOutput; x++)
{
// Calculate xyz * R
float eX = pXYZElement->m_x;
float eY = pXYZElement->m_y;
float eZ = pXYZElement->m_z;
pXYZElement->m_x = eX * m_rotationMatrix.at<float>(0, 0) + eY * m_rotationMatrix.at<float>(0, 1) + eZ * m_rotationMatrix.at<float>(0, 2);
pXYZElement->m_y = eX * m_rotationMatrix.at<float>(1, 0) + eY * m_rotationMatrix.at<float>(1, 1) + eZ * m_rotationMatrix.at<float>(1, 2);
pXYZElement->m_z = eX * m_rotationMatrix.at<float>(2, 0) + eY * m_rotationMatrix.at<float>(2, 1) + eZ * m_rotationMatrix.at<float>(2, 2);
norm = sqrt(pXYZElement->m_x * pXYZElement->m_x + pXYZElement->m_y * pXYZElement->m_y + pXYZElement->m_z * pXYZElement->m_z);
pLonLatElement->m_x = atan2(pXYZElement->m_x / norm, pXYZElement->m_z / norm);
pLonLatElement->m_y = asin(pXYZElement->m_y / norm);
pXYZElement++;
pLonLatElement++;
}
}
Given the m_rotationMatrix does not change values during the execution of ConvertXYZToLonLat function, the solution implemented in Algorithm 3 pulls those 9 calls to "at" outside the loops and gathers the 9 values in local variables a single time before the loops. This results in the following code snippet. The compiler can then keep these values in registers or cache so the code performs more efficiently.
// Optimization, pull the values out of the rotational matrix. This can
// bring a ~2x speed improvement for this function.
float m00 = m_rotationMatrix.at<float>(0, 0);
float m01 = m_rotationMatrix.at<float>(0, 1);
float m02 = m_rotationMatrix.at<float>(0, 2);
float m10 = m_rotationMatrix.at<float>(1, 0);
float m11 = m_rotationMatrix.at<float>(1, 1);
float m12 = m_rotationMatrix.at<float>(1, 2);
float m20 = m_rotationMatrix.at<float>(2, 0);
float m21 = m_rotationMatrix.at<float>(2, 1);
float m22 = m_rotationMatrix.at<float>(2, 2);
...
for (int y = 0; y < m_parameters->m_heightOutput; y++)
{
for (int x = 0; x < m_parameters->m_widthOutput; x++)
{
// Calculate xyz * R
float eX = pXYZElement->m_x;
float eY = pXYZElement->m_y;
float eZ = pXYZElement->m_z;
pXYZElement->m_x = eX * m00 + eY * m01 + eZ * m02;
pXYZElement->m_y = eX * m10 + eY * m11 + eZ * m12;
pXYZElement->m_z = eX * m20 + eY * m21 + eZ * m22;
norm = sqrt(pXYZElement->m_x * pXYZElement->m_x + pXYZElement->m_y * pXYZElement->m_y + pXYZElement->m_z * pXYZElement->m_z);
pLonLatElement->m_x = atan2(pXYZElement->m_x / norm, pXYZElement->m_z / norm);
pLonLatElement->m_y = asin(pXYZElement->m_y / norm);
pXYZElement++;
pLonLatElement++;
}
}
This code change results in an approximately 2x improvement over Algorithm 1 (i.e., 142.8002410 / 67.4700178 = 2.12).
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=3 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=CPU --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
All done! Summary of all runs:
V1c = Changed V1b to cache m_rotationMatrix instead of array indexing each time. Memory array of structure row/column layout.
warmup, 1, frame(s), 0.02331580,s, 23.31580,ms, 23315.800,us, FPS, 42.8893712
times averaging, 1000, frame(s), 0.00700279,s, 7.00279,ms, 7002.789,us, FPS, 142.8002410
total averaging, 1001, Total, 0.00701936,s, 7.01936,ms, 7019.360,us, FPS, 142.4631338
V1c = Changed V1b to cache m_rotationMatrix instead of array indexing each time. Memory array of structure column/row layout.
warmup, 1, frame(s), 0.01310980,s, 13.10980,ms, 13109.800,us, FPS, 76.2788143
times averaging, 1000, frame(s), 0.00903281,s, 9.03281,ms, 9032.813,us, FPS, 110.7074876
total averaging, 1001, Total, 0.00903708,s, 9.03708,ms, 9037.081,us, FPS, 110.6551943
Algorithm 4 optimizes Algorithm 3 by refactoring the FrameCalculations to combine the three separate calls to ComputeXYZCoords, ComputeLonLatCoords, and ComputeXYCoords into a single function. Each of the three functions had internal double loops and the computed values from each of those loops were used in subsequent loops. By combining everything into a single function, the data computations tend to stay in registers or cache memory. Determining why each step in the function occurs may be slightly more difficult, but that can be relieved by good code comments. As shown below, these code changes result in nearly a 20% improvement in speed (170.4878797 / 142.8002410 = 1.19389).
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=4 --iterations=101 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=CPU --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
All done! Summary of all runs:
V2 Single loop point by point conversion from equirectangular to flat. Array of structure row/column layout.
warmup, 1, frame(s), 0.01413620,s, 14.13620,ms, 14136.200,us, FPS, 70.7403687
times averaging, 1000, frame(s), 0.00586552,s, 5.86552,ms, 5865.520,us, FPS, 170.4878797
total averaging, 1001, Total, 0.00587395,s, 5.87395,ms, 5873.945,us, FPS, 170.2433357
V2 Single loop point by point conversion from equirectangular to flat. Two arrays for X and Y points.
warmup, 1, frame(s), 0.00703820,s, 7.03820,ms, 7038.200,us, FPS, 142.0817823
times averaging, 1000, frame(s), 0.00583512,s, 5.83512,ms, 5835.120,us, FPS, 171.3760726
total averaging, 1001, Total, 0.00583647,s, 5.83647,ms, 5836.466,us, FPS, 171.3365519
This blog introduced a framework for exploring different optimization techniques and discussed ways to increase the frames-per-second throughput including: 1) porting a speedy algorithm from Python to C++ and saving the pixel addresses from frame to frame, 2) optimizing array accesses, 3) reducing computational load by not calling the cv::Mat::at() function many times within a loop, and 4) combining separate loops into a single master loop. The combined improvements resulted in moving from 0.9273079 FPS to 170.4878797 FPS for a 183 times improvement.
In the next blog, Execution Framework and Parallel Code Optimizations, further improvements will be explored by converting the code from single thread processing to parallel processing.

|
Doug Bogia received his Ph.D. in computer science from University of Illinois, Urbana-Champaign and currently works at Intel Corporation. He enjoys photography, woodworking, programming, and optimizing solutions to run as fast as possible on a given piece of hardware. |
© Intel Corporation. Intel, the Intel logo, VTune, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request.