The previous blog, Execution Framework and Parallel Code Optimizations, utilized parallel processing to increase the algorithm speed significantly. Graphics Processing Units (GPUs) excel at doing parallel calculations, so it is worth exploring if a GPU integrated with the CPU or a discrete, stand-alone GPU could further enhance the execution speed of the algorithms. Data Parallel C++ and oneAPI make it easy to explore executing an algorithm on different pieces of hardware such as CPU, integrated GPU, discrete GPU, and other hardware such as Field Programmable Gate Array (FPGA).
Recall from the previous blog that algorithms 5 - 11 are floating point 64, and algorithms 12 - 18 are equivalent floating point 32 variants. These two variations are used interchangeably in the descriptions below.
Since the framework implemented flags for specifying the target device (see previous blog discussion of command line flags type_preference, platform, device_name, and driver_version), the same OneDevice executable can be utilized to run many of the algorithms on an integrated or discrete GPU; however, this blog series only reports on integrated GPU usage. Algorithms 0 - 4 utilize standard C++ code constructs, so those algorithms always execute on the CPU regardless of the settings of the four flags; thus, only algorithms 5 - 11 are discussed here.
The results below report on the frames per second for all six algorithms when using a single equirectangular image and changing the yaw by 10 degrees with each iteration. For these cases, the platform OpenCL was selected. The same commands can be run using the --platform=Level-Zero for interacting with the GPU instead. In 2020 when oneAPI initially launched only the OpenCL backend platform was available. Later, the Level-Zero backend was introduced. Both backends perform about the same for the code generated here, so this blog only shows the OpenCL results.
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=5 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemapping: Computes a Remapping algorithm using oneAPI's DPC++ Universal Shared Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.18890840,s, 188.90840,ms, 188908.400,us, FPS, 5.2935709
times averaging, 1000, frame(s), 0.00448163,s, 4.48163,ms, 4481.626,us, FPS, 223.1332903
total averaging, 1001, Total, 0.00466621,s, 4.66621,ms, 4666.208,us, FPS, 214.3067550
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=6 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemappingV2: Single kernel vs 3 kernels using oneAPI's DPC++ Universal Shared Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.12539840,s, 125.39840,ms, 125398.400,us, FPS, 7.9745834
times averaging, 1000, frame(s), 0.00336654,s, 3.36654,ms, 3366.542,us, FPS, 297.0406582
total averaging, 1001, Total, 0.00348864,s, 3.48864,ms, 3488.644,us, FPS, 286.6443027
DpcppRemappingV2: Single kernel vs 3 kernels using oneAPI's DPC++ Device Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.00580800,s, 5.80800,ms, 5808.000,us, FPS, 172.1763085
times averaging, 1000, frame(s), 0.00392354,s, 3.92354,ms, 3923.544,us, FPS, 254.8715901
total averaging, 1001, Total, 0.00392568,s, 3.92568,ms, 3925.676,us, FPS, 254.7332219
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=7 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemappingV3: Computes a Remapping algorithm using oneAPI's DPC++ parallel_for_work_group & Universal Shared Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.14182340,s, 141.82340,ms, 141823.400,us, FPS, 7.0510226
times averaging, 1000, frame(s), 0.00491240,s, 4.91240,ms, 4912.399,us, FPS, 203.5665428
total averaging, 1001, Total, 0.00504939,s, 5.04939,ms, 5049.393,us, FPS, 198.0435983
DpcppRemappingV3: Computes a Remapping algorithm using oneAPI's DPC++ parallel_for_work_group & Device Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.00734620,s, 7.34620,ms, 7346.200,us, FPS, 136.1247992
times averaging, 1000, frame(s), 0.00538338,s, 5.38338,ms, 5383.375,us, FPS, 185.7570693
total averaging, 1001, Total, 0.00538563,s, 5.38563,ms, 5385.630,us, FPS, 185.6793029
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=8 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
pcppRemappingV4: Computes a Remapping algorithm using oneAPI's DPC++ sub-groups to reduce scatter with Universal Shared Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.11340530,s, 113.40530,ms, 113405.300,us, FPS, 8.8179300
times averaging, 1000, frame(s), 0.00610246,s, 6.10246,ms, 6102.465,us, FPS, 163.8682208
total averaging, 1001, Total, 0.00620986,s, 6.20986,ms, 6209.857,us, FPS, 161.0343029
DpcppRemappingV4: Computes a Remapping algorithm using oneAPI's DPC++ sub-groups to reduce scatter with Device Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.00857890,s, 8.57890,ms, 8578.900,us, FPS, 116.5650608
times averaging, 1000, frame(s), 0.00667195,s, 6.67195,ms, 6671.953,us, FPS, 149.8811450
total averaging, 1001, Total, 0.00667414,s, 6.67414,ms, 6674.137,us, FPS, 149.8321065
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=9 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemappingV5: DpcppRemappingV2 and optimized ExtractFrame using DPC++ and USM Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.18274620,s, 182.74620,ms, 182746.200,us, FPS, 5.4720700
times averaging, 1000, frame(s), 0.00237170,s, 2.37170,ms, 2371.703,us, FPS, 421.6378827
total averaging, 1001, Total, 0.00255208,s, 2.55208,ms, 2552.078,us, FPS, 391.8375042
DpcppRemappingV5: DpcppRemappingV2 and optimized ExtractFrame using DPC++ and Device Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.03744720,s, 37.44720,ms, 37447.200,us, FPS, 26.7042663
times averaging, 1000, frame(s), 0.00308144,s, 3.08144,ms, 3081.440,us, FPS, 324.5236310
total averaging, 1001, Total, 0.00311604,s, 3.11604,ms, 3116.041,us, FPS, 320.9200332
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=10 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemappingV6: DpcppRemappingV5 USM but just taking the truncated pixel point Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.22290760,s, 222.90760,ms, 222907.600,us, FPS, 4.4861638
times averaging, 1000, frame(s), 0.00122949,s, 1.22949,ms, 1229.493,us, FPS, 813.3434524
total averaging, 1001, Total, 0.00145113,s, 1.45113,ms, 1451.127,us, FPS, 689.1195255
DpcppRemappingV6: DpcppRemappingV5 Device Memory but just taking the truncated pixel point Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.03739900,s, 37.39900,ms, 37399.000,us, FPS, 26.7386829
times averaging, 1000, frame(s), 0.00191971,s, 1.91971,ms, 1919.710,us, FPS, 520.9120942
total averaging, 1001, Total, 0.00195544,s, 1.95544,ms, 1955.439,us, FPS, 511.3940746
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=11 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaYaw=10 --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemappingV7: DpcppRemappingV6 USM but on CPU don't copy memory Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.22515980,s, 225.15980,ms, 225159.800,us, FPS, 4.4412901
times averaging, 1000, frame(s), 0.00122948,s, 1.22948,ms, 1229.480,us, FPS, 813.3520524
total averaging, 1001, Total, 0.00145338,s, 1.45338,ms, 1453.382,us, FPS, 688.0503458
DpcppRemappingV7: DpcppRemappingV6 Device Memory but on CPU don't copy memory Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.03550760,s, 35.50760,ms, 35507.600,us, FPS, 28.1629848
times averaging, 1000, frame(s), 0.00193682,s, 1.93682,ms, 1936.815,us, FPS, 516.3114934
total averaging, 1001, Total, 0.00197066,s, 1.97066,ms, 1970.663,us, FPS, 507.4435531
For the scenario where the viewing position moves while the image remains constant, algorithm 10 (or 17) performs well. Algorithm 11 (or 18) shows equal performance since the target device is not the CPU so the data copy into the shared memory happens equally for both algorithms. Algorithms 5 - 9 (or 12 - 16) all utilize cv::remap to extract the rectilinear image from the equirectangular image, so this does not benefit from Data Parallel C++ coding and executes on the CPU rather than the GPU.
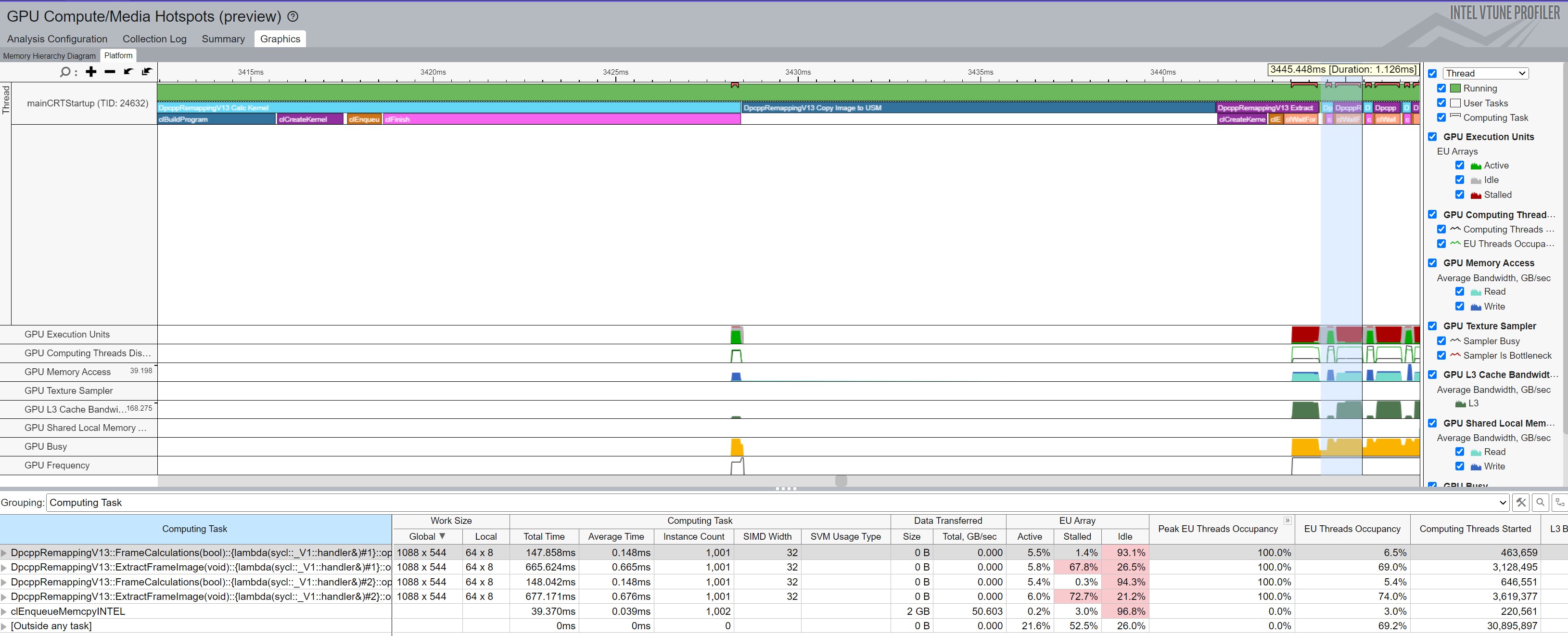
Figure 1, below, shows a zoomed-in Intel® VTune™ trace of the start of execution of Algorithm 17 (or 10) when the viewing direction changes with each iteration. At the far left (and extended to the left beyond the zoomed area) is the initial call to FrameCalculations, which submits the kernel to do the calculations. This causes clBuidProgram to compile all the kernels for the target device, create the kernel, and then execute the kernel. This falls under the "warmup" iteration in the reports above. The first call to ExtractFrameImage creates that kernel and executes it (also in the warmup time). After that, the remainder of the calls to FrameCalculations and ExtractFrameImage are much faster, as shown towards the right of the zoomed area. As highlighted in the VTune selection, the remaining frames take just over 1 millisecond, which correlates to the times shown above for --algorithm=10 at 1.229 ms.
Notice that the Copy Image happens once in the first ExtractFrameImage call. After copying the data into universal shared memory, it does not need to be copied again. This occurs since only the viewing perspective changes from call to call.
Conversely, if the image changes with each iteration and the viewing direction remains stable, Algorithms 5 - 8 (or 12 - 15) perform the best, as shown below.
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=5 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaImage --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemapping: Computes a Remapping algorithm using oneAPI's DPC++ Universal Shared Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.19017490,s, 190.17490,ms, 190174.900,us, FPS, 5.2583175
times averaging, 1000, frame(s), 0.00277925,s, 2.77925,ms, 2779.252,us, FPS, 359.8090939
total averaging, 1001, Total, 0.00296667,s, 2.96667,ms, 2966.671,us, FPS, 337.0781787
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=6 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaImage --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemappingV2: Single kernel vs 3 kernels using oneAPI's DPC++ Universal Shared Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.12423060,s, 124.23060,ms, 124230.600,us, FPS, 8.0495466
times averaging, 1000, frame(s), 0.00279086,s, 2.79086,ms, 2790.855,us, FPS, 358.3130692
total averaging, 1001, Total, 0.00291242,s, 2.91242,ms, 2912.425,us, FPS, 343.3564960
DpcppRemappingV2: Single kernel vs 3 kernels using oneAPI's DPC++ Device Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.00584060,s, 5.84060,ms, 5840.600,us, FPS, 171.2152861
times averaging, 1000, frame(s), 0.00275810,s, 2.75810,ms, 2758.100,us, FPS, 362.5684479
total averaging, 1001, Total, 0.00276142,s, 2.76142,ms, 2761.418,us, FPS, 362.1328169
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=7 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaImage --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemappingV3: Computes a Remapping algorithm using oneAPI's DPC++ parallel_for_work_group & Universal Shared Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.14006830,s, 140.06830,ms, 140068.300,us, FPS, 7.1393741
times averaging, 1000, frame(s), 0.00278156,s, 2.78156,ms, 2781.563,us, FPS, 359.5100640
total averaging, 1001, Total, 0.00291895,s, 2.91895,ms, 2918.950,us, FPS, 342.5888919
DpcppRemappingV3: Computes a Remapping algorithm using oneAPI's DPC++ parallel_for_work_group & Device Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.00718330,s, 7.18330,ms, 7183.300,us, FPS, 139.2117829
times averaging, 1000, frame(s), 0.00275300,s, 2.75300,ms, 2752.998,us, FPS, 363.2402996
total averaging, 1001, Total, 0.00275764,s, 2.75764,ms, 2757.642,us, FPS, 362.6286440
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=8 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaImage --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemappingV4: Computes a Remapping algorithm using oneAPI's DPC++ sub-groups to reduce scatter with Universal Shared Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.11223650,s, 112.23650,ms, 112236.500,us, FPS, 8.9097575
times averaging, 1000, frame(s), 0.00277617,s, 2.77617,ms, 2776.168,us, FPS, 360.2086963
total averaging, 1001, Total, 0.00288578,s, 2.88578,ms, 2885.785,us, FPS, 346.5261841
DpcppRemappingV4: Computes a Remapping algorithm using oneAPI's DPC++ sub-groups to reduce scatter with Device Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.00856960,s, 8.56960,ms, 8569.600,us, FPS, 116.6915609
times averaging, 1000, frame(s), 0.00275504,s, 2.75504,ms, 2755.043,us, FPS, 362.9706886
total averaging, 1001, Total, 0.00276105,s, 2.76105,ms, 2761.054,us, FPS, 362.1805629
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=9 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaImage --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemappingV5: DpcppRemappingV2 and optimized ExtractFrame using DPC++ and USM Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.17899840,s, 178.99840,ms, 178998.400,us, FPS, 5.5866421
times averaging, 1000, frame(s), 0.01785927,s, 17.85927,ms, 17859.275,us, FPS, 55.9933150
total averaging, 1001, Total, 0.01802053,s, 18.02053,ms, 18020.534,us, FPS, 55.4922498
DpcppRemappingV5: DpcppRemappingV2 and optimized ExtractFrame using DPC++ and Device Memory on Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.03800280,s, 38.00280,ms, 38002.800,us, FPS, 26.3138506
times averaging, 1000, frame(s), 0.02621079,s, 26.21079,ms, 26210.794,us, FPS, 38.1522209
total averaging, 1001, Total, 0.02622329,s, 26.22329,ms, 26223.288,us, FPS, 38.1340440
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=10 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaImage --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemappingV6: DpcppRemappingV5 USM but just taking the truncated pixel point Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.22567630,s, 225.67630,ms, 225676.300,us, FPS, 4.4311255
times averaging, 1000, frame(s), 0.01664422,s, 16.64422,ms, 16644.224,us, FPS, 60.0809029
total averaging, 1001, Total, 0.01685351,s, 16.85351,ms, 16853.510,us, FPS, 59.3348225
DpcppRemappingV6: DpcppRemappingV5 Device Memory but just taking the truncated pixel point Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.03744570,s, 37.44570,ms, 37445.700,us, FPS, 26.7053360
times averaging, 1000, frame(s), 0.02635154,s, 26.35154,ms, 26351.536,us, FPS, 37.9484520
total averaging, 1001, Total, 0.02636313,s, 26.36313,ms, 26363.132,us, FPS, 37.9317608
src\DPC++-OneDevice\x64\Release\OneDevice.exe --algorithm=11 --iterations=1001 --yaw=10 --pitch=20 --roll=30 --deltaImage --typePreference=GPU --platform=OpenCL --img0=images\IMG_20230629_082736_00_095.jpg --img1=images\ImageAndOverlay-equirectangular.jpg
...
DpcppRemappingV7: DpcppRemappingV6 USM but on CPU don't copy memory Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.22377680,s, 223.77680,ms, 223776.800,us, FPS, 4.4687385
times averaging, 1000, frame(s), 0.01710737,s, 17.10737,ms, 17107.370,us, FPS, 58.4543373
total averaging, 1001, Total, 0.01731408,s, 17.31408,ms, 17314.079,us, FPS, 57.7564667
DpcppRemappingV7: DpcppRemappingV6 Device Memory but on CPU don't copy memory Intel(R) OpenCL HD Graphics Intel(R) UHD Graphics 630 31.0.101.2125
warmup, 1, frame(s), 0.03754000,s, 37.54000,ms, 37540.000,us, FPS, 26.6382525
times averaging, 1000, frame(s), 0.02627702,s, 26.27702,ms, 26277.016,us, FPS, 38.0560714
total averaging, 1001, Total, 0.02628900,s, 26.28900,ms, 26289.002,us, FPS, 38.0387208
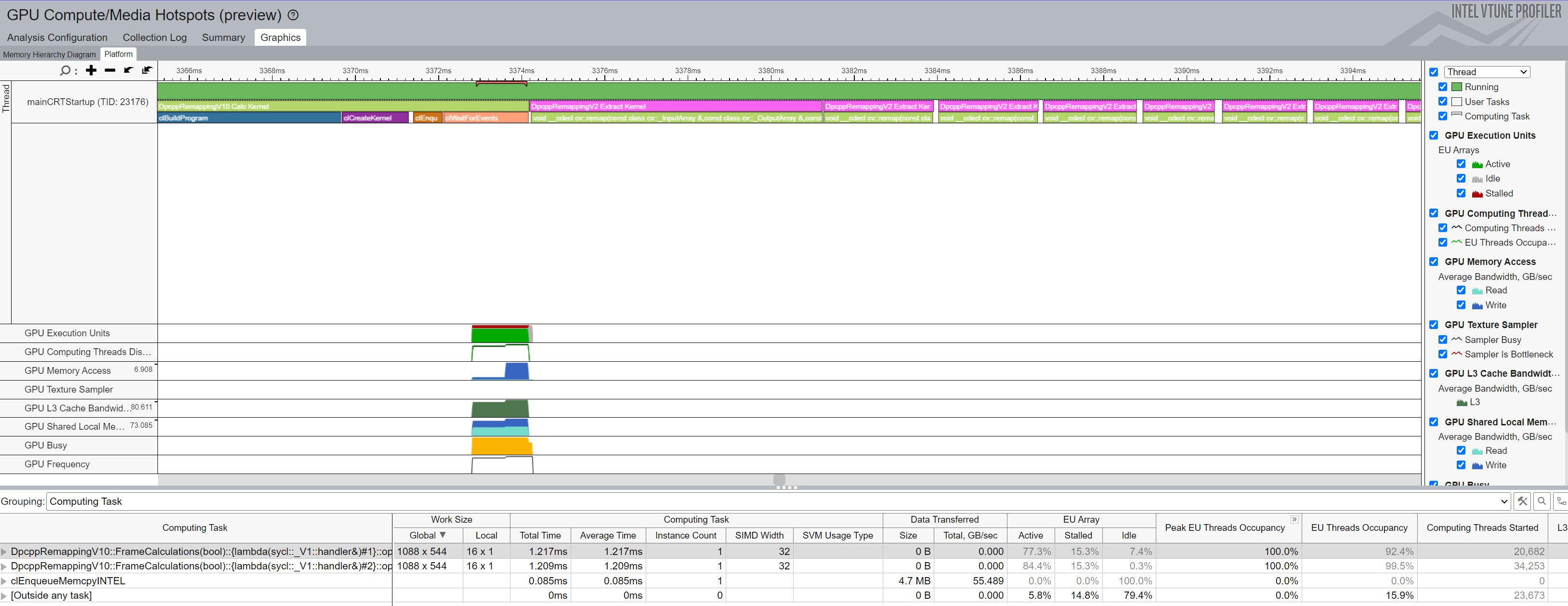
Figure 2 below shows the VTune output from Algorithm 14 (or 7). Algorithms 5 - 8 or (12 - 15) do the calculations for the view on the GPU a single time at startup (as seen by the Calc Kernel call on the left side of the VTune figure), and the remapping of those data points to the rectilinear image happen on the CPU each iteration so the large images remain local to the CPU thereby saving the copy time.
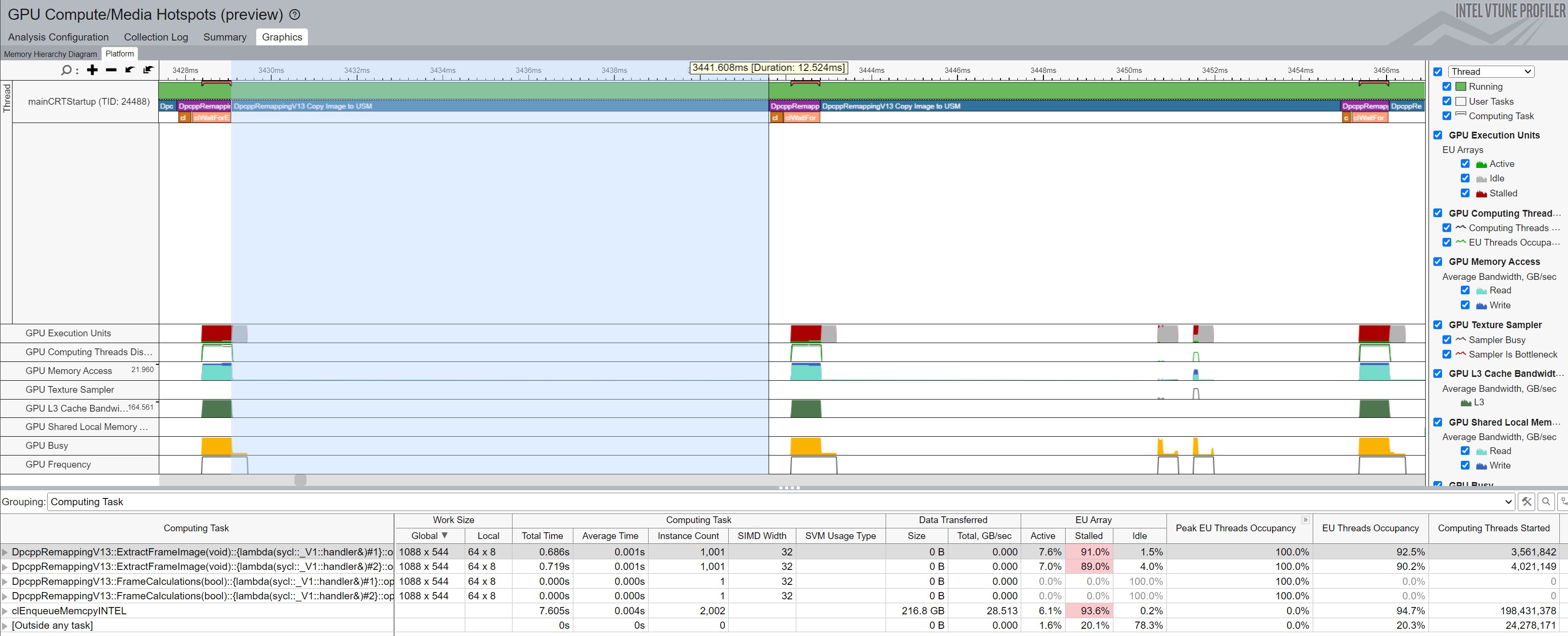
When the image changes with each iteration while using algorithms 9 - 11 (or 16 - 18), the full equirectangular image must be copied to the shared memory every time, as shown in Figure 3 below. This adds around 12 milliseconds to each iteration and greatly impacts the frames per second that can be computed since the test images are 11,968 x 5,984 pixels, thereby requiring a lot of data to get copied.
These results highlight the importance of understanding the scenario(s) that require support and selecting the right algorithm according to the scenario. DPC++ and oneAPI have the advantage of allowing a programmer to code in a uniform language regardless of the target device; however, optimizing algorithms may require tailoring the code according to the hardware features, considering optimal ways to access the data, and exploring with tests or tools how the code behaves under different conditions.
Everything up until this point has targeted a single device at a time. Might executing on both the CPU and GPU simultaneously make sense? One of the tag lines used with oneAPI says "No Transistor Left Behind", so how can the code be changed to send some work to the CPU and simultaneously some work to the integrated GPU? This turned out to be a larger code change than originally expected. The original hope was to submit work to one device without a queue wait() call and then submit the next set of work to the other device and then wait() for either to complete, submit the next work to the device(s) that completed, and continue. However, an Application Programming Interface (API) call to wait() for multiple queues simultaneously could not be found (please post a comment if there is one). Therefore, the code was altered to run two standard C++ threads, and the primary thread doles out work to the sub-threads, and each sub-thread manages one of the two devices and thus can wait() without blocking the other thread's execution. The main thread uses condition variables and mutexes to pass information back and forth between the three threads. This code can be found in the TwoDevices solution. Since TwoDevices depends on oneAPI / DPC++, thus, only algorithms 5 - 19 are supported (algorithm 19 is introduced later in this blog).
Executing the OneDevice code with algorithm 17 (or 10) results in the following output when running on the CPU and changing the image with each iteration. Algorithm 17 was utilized since algorithm 18 favors the CPU since it does not copy the images to universal shared memory. Since TwoDevices must copy the data at least to the GPU, it seemed reasonable to try to make the amount of work required by each program as similar as possible.
Executing the TwoDevices code with the same configuration outputs the following. Looking at the ALL times averaging line shows that the CPU and GPU were collectively able to execute at 116 FPS. The CPU did 71 FPS, and the GPU did nearly 45 FPS. While the higher FPS is a fantastic result, there seemed to be something amiss. Notice that the CPU FPS is higher than it was for OneDevice. That should not be possible, so further investigation was needed.
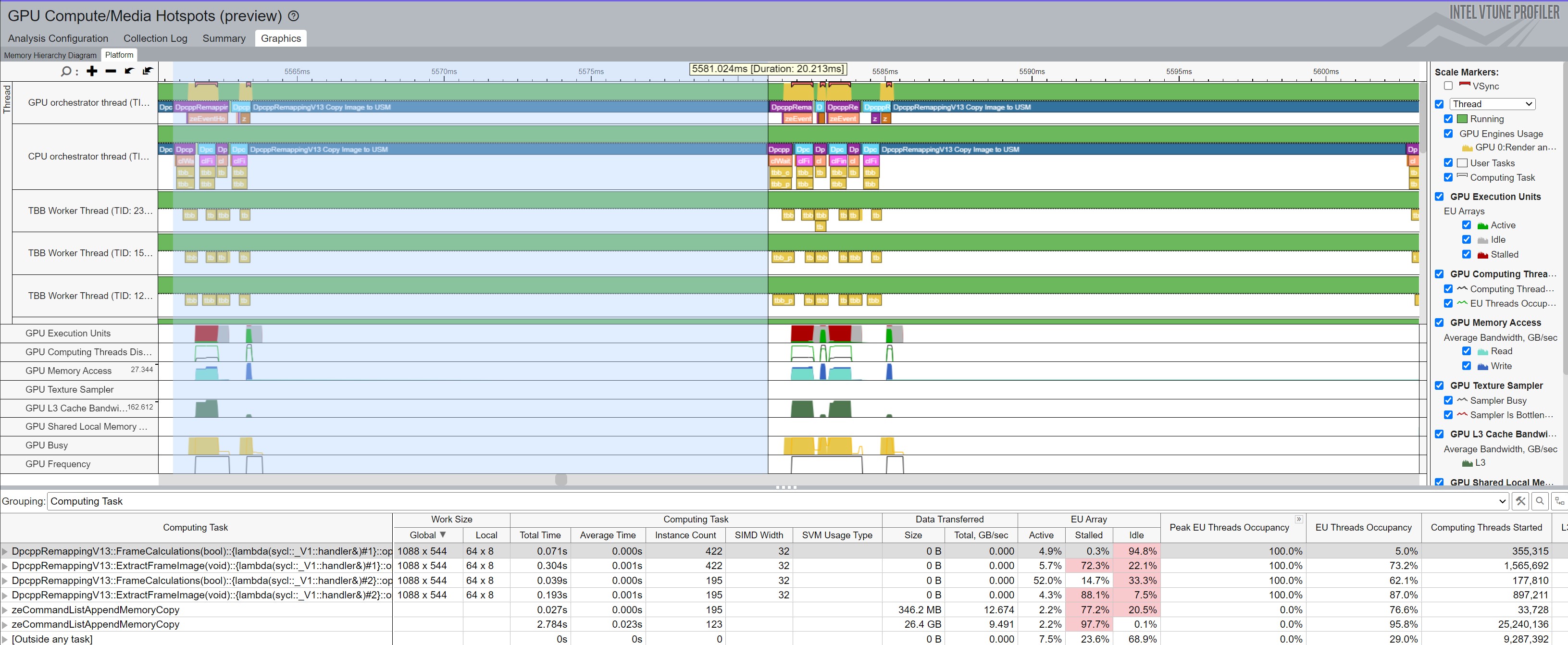
VTune to the rescue! Full disclosure: the VTune figure was captured when both --deltaImage and --deltaYaw=10 were set, but the root cause remains the same even when only --deltaImage is used. Figure 4 zooms in on the code execution that explains the above results. Notice on the left that the CPU and GPU orchestrator threads both kick off working on a frame, and they both copy the image before extraction. However, due to a leftover optimization from OneDevice, the TwoDevices code essentially cheats. Assume at the far left that the CPU receives image 0 and the GPU receives image 1. The first light blue box for the CPU represents the start of calculating the frame's viewport. That means the CPU completed working on image 0, and the main thread gave it the next round of work, which would be image 0 (again) since the GPU received image 1. Thus, the CPU does not need to make a copy since it receives the same index again. It finishes that work quickly and receives image 1 from the main thread, so now the long, dark blue bar indicates a copy was made. Meanwhile, the GPU completes its work and receives image 0 this time. Since it had image 1 last time, it also must make a copy. In the center of the figure, both the CPU and GPU can skip copying since, at least for that period, they are getting the same image they already had. A little later, they are given an image they did not have, requiring them to make a copy. This allows the CPU to perform faster in the TwoDevices code when compared to the OneDevice code.
To make TwoDevices more comparable to OneDevice, --algorithm=19 was added to the code base. If the --deltaImage flag is set, an image copy is always made regardless of whether the device already has that image in its memory.
Now, the results appear more reasonable even with negligible speedup. It seems likely that the code is memory speed constrained since much of the time that the CPU and GPU operate, they copy data around in memory. Later in this blog, the same code executes on a machine with higher memory performance, and the overall speed increases by 50% versus OneDevice. More research would be required to confirm this code is memory bandwidth-constrained, but the current data suggests this to be true.
Most likely, further code optimizations remain possible. For instance, looking closely at the VTune results of TwoDevices suggests that the GPU remains idle longer in the TwoDevices code versus the OneDevice code. Using multiple threads and having them communicate via mutexes and condition variables probably creates slight delays in handing more work to the GPU (or the CPU, for that matter). Each time the queue to the device becomes empty, that device stops doing anything useful. Since the DPC++ queues can have more than one work item queued at a time; one possible resolution would be to add more than one frame at a time to the device queues. That way, they can immediately begin on the next when they finish executing one work item.
An opportunity presented itself to upgrade the hardware being used to execute OneDevice and TwoDevices. The new machine is an Intel® i9-12900 machine with the following components:
Gigabyte Z690 ATX Alder Lake-S Desktop
Processor 12th Gen Intel® Core™ i9-12900 2.40 GHz
Installed RAM 128.0 GB (128 GB usable)
System Type 64-bit operating system, x64-based processor
Intel oneAPI Base Toolkit 2024.0
Microsoft Visual Studio 2022
A handy website for getting lots of details about any Intel processor is https://ark.intel.com/. Searching for the two processors results in https://ark.intel.com/content/www/us/en/ark/products/186605/intel-core-i9-9900k-processor-16m-cache-up-to-5-00-ghz.html and https://ark.intel.com/content/www/us/en/ark/products/134597/intel-core-i912900-processor-30m-cache-up-to-5-10-ghz.html.
Using these pages, the i9-9900K has 8 Cores and 16 threads, 3.6 GHz frequency with a maximum turbo frequency of 5.00 GHz, a 95 Watts Thermal Design Power, and utilizes DDR4-2666 memory. The integrated GPU is Intel UHD Graphics 630 with a base frequency of 350 MHz and a maximum frequency of 1.2 GHz.
The i9-12900 has 16 cores (8 performance and 8 efficient) with 24 hardware threads. In recent processors, there are two types of cores. The performance cores handle heavy computing while the efficient cores are more energy efficient and handle the lighter tasks so the performance cores do not have to context switch to those tasks. The base frequency of the efficient cores is 1.8 GHz, and the maximum frequency is 3.8 GHz. The performance core's base frequency is 2.4 GHz with a max of 5.00 GHz. These processors have a base power of 65 Watts, supporting bursts up to 202 Watts. The processors use DDR5 up to 4800 MT/s or DDR4 up to 3200 MT/s. The integrated GPU is Intel UHD Graphics 770 with a base frequency of 300 MHz and a maximum of 1.55 GHz.
Running OneDevice on the CPU and adjusting the viewing perspective for each iteration results in the following output. The 1275 FPS executes about 30% faster than the i9-9900K (963.7175386 / 1274.997944 = 1.322999627). Altering the image and changing both the image and the viewing perspective also show a 30+% improvement in speed with 36 and 39%, respectively.
Running OneDevice on the GPU and adjusting the viewing perspective for each iteration results in the following output. The 1033 FPS executes about 20% faster than the i9-9900K (866.5268355 / 1033.690661 = 1.192912462). Altering the image shows a 27% improvement, and altering the image and viewing perspective improves by 28%. Thus, the newer processor performs better with a lower base power draw.
One extra interesting result is how the TwoDevices code ran. There was minimal improvement on the Intel i9-9900K when executing the --deltaYaw=10 on two devices versus one device. However, with the i9-12900, there is a marked improvement of 51% using algorithm 19 (2102.2293626 / 1391.6927044 = 1.5105).
For the case where the image changes with each iteration, the results on the i9-12900 are below and represent a speedup of 33% (105.0773895 / 78.7852222 = 1.33371). This supports the earlier hypothesis that the code is memory bandwidth bound since this computer has DDR5 4800 memory and performs better concurrently.
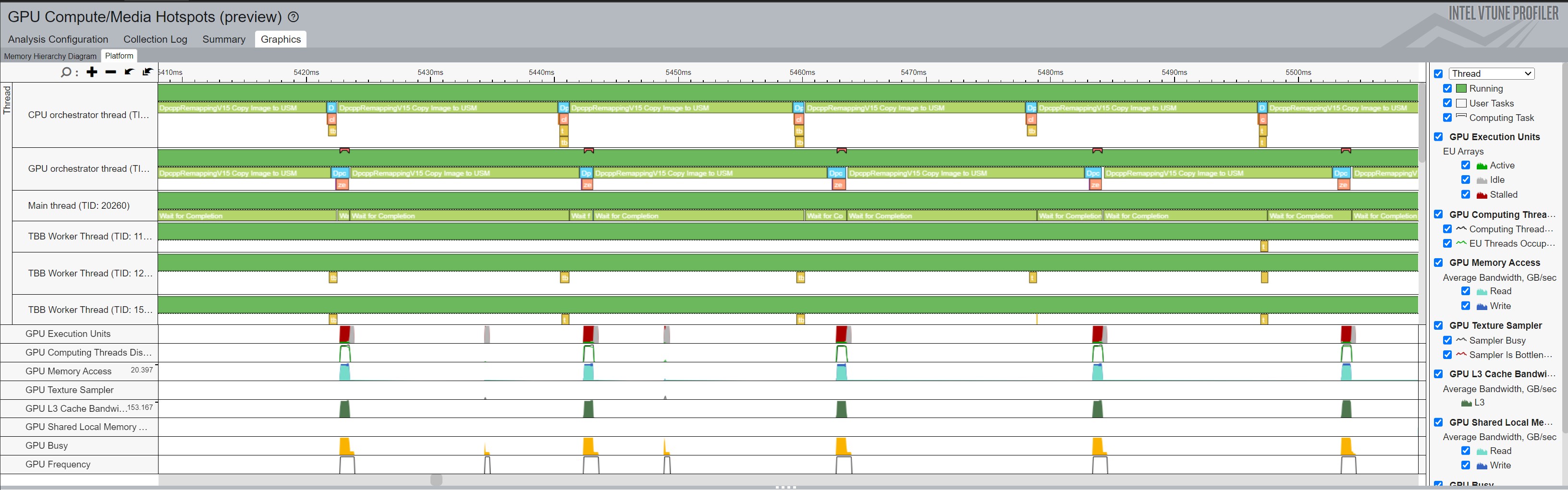
Figure 5 below shows a zoomed-in view of VTune as the code operates. Note the large overlap in the Copy Image to USM operations between the CPU and GPU, which would both be contending for the same memory.
This blog covered running the code on the integrated GPU and discussed how the amount of data required to transfer from CPU to GPU impacts the overall performance. Next, the new code showed how to target two devices in the system simultaneously but also pointed out system limitations that may constrain the amount of upside this brings to the overall performance. Finally, a newer machine performed better despite a lower base power budget. This machine also supported the hypothesis memory bandwidth constrains the overall code performance.
VTune provided numerous insights into the code and helped find optimization points, but it also helped visualize algorithm errors so those could be corrected.

|
Doug Bogia received his Ph.D. in computer science from the University of Illinois, Urbana-Champaign, and works at Intel Corporation. He enjoys photography, woodworking, programming, and optimizing solutions to run as fast as possible on a given piece of hardware. |
© Intel Corporation. Intel, the Intel logo, VTune, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request.